

If you are working as a Data Scientist or an AI/ML engineer your one of the major challenge is running parallel ML models for training or for prediction . People say we can make use of Distributed systems like big data systems spark , hadoop for parallel processing . But to understand the use case , our problem is not with data processing with big data its with parallel modelling . Also many suggestions are there by using multithreading or async calls to handle the parallel load , but by the end you are utilizing your personal system resources . Is there any way around to make things fast and cheap ?
Yes there is a little hack to make life easy . In this blog I am gonna give you a walk through on how to make use of AWS Lambda for independent parallel modelling .
Before get started , a slight insights about necessary concepts
What is Serverless Computing ?
Serverless computing is a cloud-computing execution model in which the cloud provider runs the server, and dynamically manages the allocation of machine resources. Pricing is based on the actual amount of resources consumed by an application, rather than on pre-purchased units of capacity ( AWS EC2 ). To know more : Serverless Computing Pros & Cons
What is AWS Lambda ?
AWS Lambda is an event-driven, serverless computing platform provided by Amazon as a part of Amazon Web Services. It is a computing service that runs code in response to events and automatically manages the computing resources required by that code . In short , Don’t care about the system configuration , Just run the code we will take care the rest.
 To know more : AWS Lambda Intro Video
To know more : AWS Lambda Intro Video
Why AWS Lambda not any other provider ?
As per my research and experience , AWS Lambda functions are relatively cheap and provides other facility like orchestration , API Gateways , application integration , good logging systems , analytical and data integration support etc . But there are other providers like Azure Functions , Google Cloud , IBM Functions etc . This kind of service is shortly known as FaaS ( Function as a Service )
Now you got the underlying concept , so I think you can assume why we are using it for parallel ML modelling . Lets explore with some ML Scenarios and code .
Step 1 : Make your AWS account ready with Lambda
- Sign Up and Create AWS Account with Free Tier Access
- Search Lambda Service in their service page
![Image result for aws lambda dashboard]()
- Select Create Function -> Author from Scratch. Then give the necessary configurations
- After clicking Create Function it gets you to Function Dashboard . Now you are ready to go . Feel free to play and try the configuration settings in the dashboard To play with AWS Lambda Try this : AWS Lambda Tutorial
Step 2: Preparing the Dataset and Model Functions ( Traditional ):
For example , we consider Iris classification problem . In this problem , we need to train multiple models based on the dataset chunks . If we utilize our system , it takes lot of time due to sequence modeling and availability of system resource . Here is a sample code
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
import numpy as np
import pandas as pd
import pickle
from sklearn import metrics
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
# Load the dataset
data = pd.read_csv('Iris.csv')
# Data Part #
# we are copying the data to 1000 copies to assume the sceanario
data_dict = {}
for i in range(0,1000):
key_name = "data_" + str(i)
data_dict[key_name] = data.copy()
# Modelling Part #
# Now we have 1000 dataset , so we have to model 1000 models on same algorithm
for data_name , dataset in data_dict.items():
X = dataset.drop(['Id', 'Species'], axis=1)
y = dataset['Species']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.4, random_state=5)
knn = KNeighborsClassifier(n_neighbors=12)
knn.fit(X, y)
# Save the model
pkl_filename = data_name + ".pkl"
with open(pkl_filename, 'wb') as file:
pickle.dump(knn, file)
Here I am building 1000 models sequentially in my local system . Now I breakdown the code and replace it with lambda.
Step 3: Building with AWS Lambda Handler & Deployment Package:
We are gonna now replace traditional model building with AWS Lambda
AWS Lambda has two major components :
- Handler : It is a function in your code, that AWS Lambda can invoke when the service executes your code
- Deployment Package : A deployment package is a ZIP archive that contains your function code and dependencies. You need to create a deployment package if you use the Lambda API to manage functions
In our example , our target is to replace sequencing modelling part with AWS Lambda and threading . So we first identify the code which should be handled by our AWS Lambda.
1
2
3
4
5
6
7
8
9
10
11
for data_name , dataset in data_dict.items():
X = dataset.drop(['Id', 'Species'], axis=1)
y = dataset['Species']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.4, random_state=5)
knn = KNeighborsClassifier(n_neighbors=12)
knn.fit(X, y)
# Save the model
pkl_filename = data_name + ".pkl"
with open(pkl_filename, 'wb') as file:
pickle.dump(knn, file)
This part should be replaced with threading and lambda calls . Now we create a lambda_handler.py which contains the replacing the code or the model part.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
import pandas as pd
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
def handler(event, context):
try:
dataset = pd.DataFrame(event["data"])
X = dataset.drop(['Id', 'Species'], axis=1)
y = dataset['Species']
X_train, X_test, y_train, y_test = train_test_split(X, y,
test_size=0.4, random_state=5)
knn = KNeighborsClassifier(n_neighbors=12)
knn.fit(X, y)
except Exception as error:
return { 'statusCode': 500, 'body': str(error) }
return {'statusCode': 200,'body': "Model Successful"}
Note : In this code I am skipping storing of models because it varies based on requirment . You can store the model in Cloud DB like AWS S3 (best way) or you can serialize it and send as file.
You can notice two major key terms
- event : AWS Lambda uses this parameter to pass in event data to the handler. This parameter is usually of the Python
dicttype. It can also belist,str,int,float, orNoneTypetype. - context: AWS Lambda uses this parameter to provide runtime information to your handler.
Now your lambda handler file is ready , next step is creating a deployment package . It is nothing but making a zip file which contains your lambda_handler.py and its supporting packages .
Follow the steps carefully :
- Consider aws_lambda as my project folder . Inside that you already have lambda_handler.py
- Install all the necessary pacakges in package folder inside project folder. Here we are using scikit-learn and pandas packages
1
$ pip install --target ./package scikit-learn
1
$ pip install --target ./package pandas
- You have lambda_handler.py file and package folder in your aws_lambda folder
- Compress the files as function.zip file
1
$ cd package
1
$ zip -r9 ${OLDPWD}/function.zip .
1
$ cd $OLDPWD
1
$ zip -g function.zip lambda_handler.py
- You can see a function.zip file inside your aws_lambda folder .
Step 4: Exporting Deployment Package & Lambda Invocation :
Now you have your lambda function in aws configured and the function.zip depolyment package in your local system is ready .There are three ways of implementing functions in lambda:
- Inline : If its a simple function which does not need any additional libraries and overheads you can use this
- Upload zip file: If your deployment package ( function.zip ) is not more than 10MB you can directly import your function.zip and run it.
- Upload a file from Amazon S3: For function.zip file which is more than 10MB , you can upload it in AWS S3 bucket and give the S3 file URL in the field value .
In our case we are using Scikit and Pandas package in our function.zip it exceeds 10Mb , so we are following S3 approach . I hope the remaining two are easy which you can try by yourself.
- Create a S3 bucket or use existing bucket in AWS and upload the function.zip file
- Copy the S3 file url and paste in the lambda function field remember to follow the 4 steps 1) Select the function code as “Upload file S3” 2) Paste the S3 file URL 3) Set the Runtime version correct ( Python 3.6 ) 4) In handler field , the value preceeding the dot is file of handler function what we wrote in function.zip ( lambda_handler) then the value succedding the dot is the function inside lambda_handler.py ( handler ) so it is lambda_handler.handler
- Finally click Save . Now your aws lambda is ready to go but how you will invoke it let see in the next step.
Step 5: Invocation Function for Lambda Functions & Async Calls :
Before getting to this , we need to understand that we gonna call lambda functions asynchronously calls so that it breaks the sequence chain . AWS Lambda has two types of Invocations
-
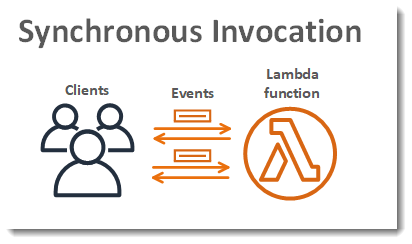
Synchronous Invocation : When you invoke a function synchronously, Lambda runs the function and waits for a response. When the function execution ends, Lambda returns the response from the function’s code with additional data, such as the version of the function that was executed. The input to function ( parameters ) will be encoded as string as send by the invocation to the function . The max size of payload is 6MB
![Clients invoke a function synchronously and wait for a response.]()
-
Asynchronous Invocation: When you invoke a function asynchronously, you don’t wait for a response from the function code. You hand off the event to Lambda and Lambda handles the rest. The payload is encoded as string as previous invocation and the maximum size is 256 KB
In our case , the dataset size in 5KB and we are storing the response as per the case there is no need of collection response from lambda function so we are using asynchronous invocation.
To invoke lambda functions in python scripts we need to use Boto library and also your aws credentials. In our existing traditional code make the changes accordingly
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
import numpy as np
import pandas as pd
import boto3
import json
# AWS CREDEDNTIALS which you can find in your AWS Account IAM Role page
client = boto3.client('lambda',
region_name = YOUR_REGION_NAME (EG: ap-east-q ,
aws_access_key_id = YOUR_ACCESS_KEY_ID,
aws_secret_access_key= YOUR_SECRET_KEY)
def send_request(data):
# Asynchronous Call
result = client.invoke(FunctionName="lambda_tutorial_ml",
InvocationType='Event',
Payload=json.dumps({"data":data},default=str))
# Load the dataset
data = pd.read_csv('Iris.csv')
# Data Part #
# we are copying the data to 1000 copies to assume the sceanario
data_dict = {}
for i in range(0,1000):
key_name = "data_" + str(i)
data_dict[key_name] = data.copy()
# Modelling Part #
# Now we have 1000 dataset , so we have to model 1000 models on same algorithm
# Boto Invocation Call
for data_name , dataset in data_dict.items():
data = dataset.to_dict(orient="records")
send_request(data)
When you run this code , you are invoking the lambda functions . To check the status of your hits you can use CloudWatch inbuilt feature in AWS Lambda
Prediction of Models in Lambda :
The procedure is same as the above you will be saving your trained models in S3 and you will be writing a handler function to load_model, predict and save results . You will be using the boto to invoke the function to get the result.
Note : This example is just for demo and easy understanding . The real case will be more complex . Analyze whether your system needs this feature and implement.
Hurrah !!! You successfully learnt how to build a serverless computing environment for training and prediction models
Also there are more complex things like trigger , destination , concurrency etc in lambda . Please checkout the below reference links to move forward.
Advantages of using Serverless Framework for ML:
- Dynamic creation of system to handle load
- Better service accessibility in Cloud
- Less time to configure and setup things up
- No need to worry of system configuration
- Automatic system scaling based on need
- Cheap and time saving
Comments powered by Disqus.